Pseudonymization is a well-known technique in data privacy. However, although it is a sensible security precaution, it cannot make your application GDPR compliant by itself. In this blog we look in more detail at pseudonymization, and when and how to use it.
As a company, we often find ourselves having to explain the concept of pseudonymization. In fact, it is probably the aspect of data protection that is most misunderstood. So, we have decided to produce a simple guide to pseudonymization.
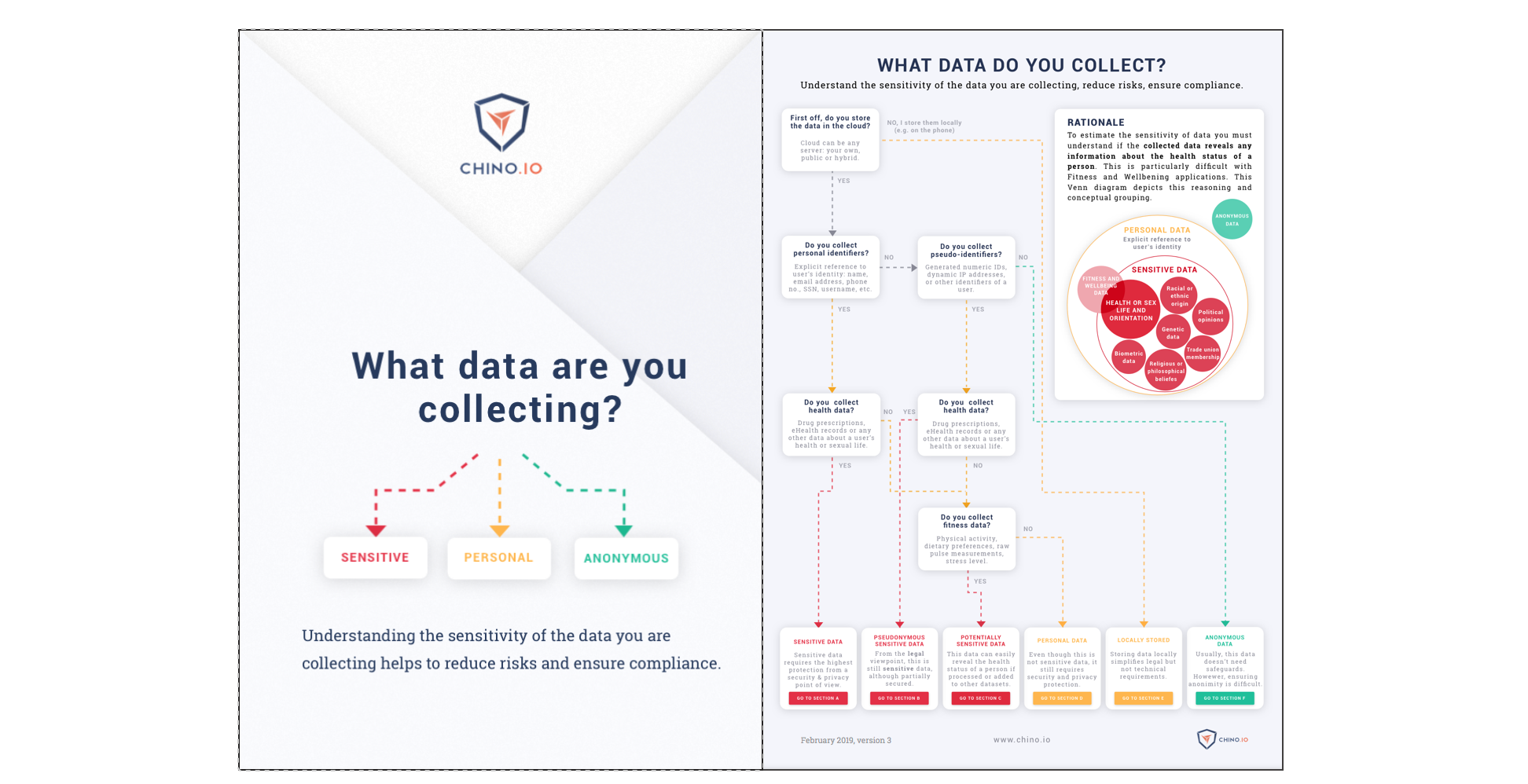
What is pseudonymization?
Pseudonymization simply means replacing all personal identifiers with some form of pseudonym. This could be an actual name, but more often it’s a numeric or alphanumeric identifier. The pseudonym is usually generated randomly.
Why should I use it?
Pseudonymization is used in data security to conceal the identity of a person. Sensitive data can then be stored with the pseudonym and the list of pseudonyms and related personal information is stored separately. This makes it harder for an attacker to steal the data.
When should I use pseudonymization?
Whenever you have sensitive data to store it is a good idea to use pseudonymization. GDPR says that you should take all reasonable steps to protect data, which would include the use of pseudonymization. In the USA, HIPAA mandates the use of pseudonymization for data sharing. This means you should view pseudonymization as a minimum step if you are sharing or storing any sensitive data.
What are the implications of using pseudonymization?
Under HIPAA, data that has had specific fields pseudonymized is treated as anonymous. That means the data can then be freely shared with 3rd parties. Under GDPR things are more complicated. In 2014, the EU’s Article 29 Working Party ruled that pseudonymized data is still personal data. As a result, pseudonymized data must still be treated as personal data in the EU.
Why isn’t pseudonymous data secure enough?
The problem with pseudonymized data is re-identification. By cross-referencing pseudonymized data with external data sources it is often possible to re-identify the individual. One of the most famous such incidents happened in 2006. Netflix ran a competition to try and find a better recommender system. They released data on the viewing habits of a large number of viewers. Researchers were able to cross reference the data with reviews left on IMDB and managed to re-identify a number of users.
What is the difference with anonymization?
Data anonymization involves completely removing all personal identifiers from the data. This is done in several ways including:
- Generalisation. E.g. changing age 27 to age 20-30 or only giving the district rather than the street address.
- Swapping. E.g. mixing data fields up so that the overall data still looks the same.
- Perturbation. E.g.modifying the data by rounding someone’s weight to the nearest 5kg.
There are various ways to anonymise data in a way that guarantees the anonymity. These include differential privacy and k-anonymity. Anonymous data is excluded from both HIPAA and GDPR. However, it is only really useful when you want to analyse trends across all the data.
Where does encryption fit in the picture?
Sometimes there is confusion between data encryption and anonymization or pseudonymization. We often come across people that are convinced the data they store is anonymous because it has been pseudonymized and encrypted. However, this data is actually still defined as personal for GDPR purposes. Moreover, we often see people using weak forms of encryption where the theft of a single key decrypts a large share of the data.
How can I implement pseudonymization?
The Chino.io API makes it extremely simple to implement pseudonymization. We would always recommend you use this when storing health data. If you are intending to do data sharing then we view it as an essential step. N.B. data that is pseudonymized can only be shared with the consent of the person involved. Furthermore, with our API, data is encrypted at the record level, which is the most secure form of encryption for such data.